
MPESA RECEIPT SERIALIZATION
Introduction
The main purpose of this particular article if I may call it so about a tweet that popped in my thread a few weeks ago. How the largest mobile service provider in Kenya sequentially labels their innovative mobile money receipts. The receipts are usually in SMS (Short Message Service) format, every transaction you make you receive the SMS with receipt details. Details of amount sent, name, mobile number of recipient and balance of your account.
According to the tweet, the initial two letters change every year, with tweeps even affirming the same. Coming from my various amusements in life, where data is king and interestingly being among the very few people with their backed up MPesa SMS’s dating back to 2012. I used to backup my SMS after a certain period, this was not because I believed in backing up, on the contrary it was because I had my first Andriod flagship phone pet-named “Ideos” manufactured by Hauwei, model U8150 IDEOS. This gadget packed 512MB storage, 256MB RAM, 3.2MP back camera and wait for it running android version 2.2 Froyo now we are on version 10.0.
Now starts the fun part, using my somewhat experience in data analysis I embarked on the journey of retrieving all my old backed up SMS. Best part about it they are saved as XML thanks to the app I downloaded back in 2012 SMS Backup & Restore interestingly it runs on even the current versions of android talk of backward compatibility with native apps, back then the logo was blue and not current green.
Intended approach
Fair warning I will be going full macho technical, do bear with me if my lingo is not straight forward, the plus is still you can be able to follow. FYI you can skip the next parts go straight to conclusion.
After merging all the XML files and then filtering out MPesa messages. I proceeded to used regular expression (Regex) to pick the receipt number and the date the SMS was received. The receipt is text format and includes other details such us the number you are sending to the name of the recipient, the amount being sent or received, your MPesa account balance and additional promotional items.
Setup
Loading libraries I will be using.
#loading necessary
library("stringr") #String manipulation
library("tidyr") #Tidying data
library("dplyr") #data manipulation
library("openxlsx") #Reading excel
library("xml2") #Reading xml and manipulating xml docs
library("purrr") #Functional mapping across vectors
library("lubridate") #date manipulation
library("ggplot2") #Grammar of graphics. I normally find myself loading both tidyr and dplyr because I end up using both freely. Truth be told I end up forgetting which functions come from which package.
Reading XML
As mentioned the back of the texts are in XML format. 24 XML files starting from October 2012 to Jan 2020, we shall explore this later.
I did some preprocessing of loading the texts, I will show you the steps I used but won’t avail the data. It’s a dump of my personal messages.
All the XML files are in one folder, we load the file names from the folder. Using list.files and the argument pattern = ".xml$" to ensure we only pick .xml files.
list_files <- list.files("../SMSBackupRestore/", pattern = ".xml$")
list_filesNow, that we have the list of files names we need to load it up to R. Challenge reading each file then merging them together into one whilst ensuring that you optimize your memory usage.
Created function func_xml_work to read and manipulate the xlm code. Snippet of how the xml looks initially below.
<?xml version='1.0' encoding='UTF-8' standalone='yes' ?>
<!--File Created By SMS Backup & Restore v10.06.102 on 16/01/2020 18:39:33-->
<smses count="2" backup_set="f24cc90b" backup_date="1579189173334">
<sms protocol="0" address="MPESA" date="1506773148699" type="1" subject="null" body="LIU5GRAAHF confirmed.You bought KshXXX of airtime on 30/9/17 at 3:05 PM.New M-PESA balance is KshXX. Transaction cost, Ksh0.00." toa="null" sc_toa="null" service_center="null" read="1" status="-1" locked="0" date_sent="1506773145000" sub_id="-1" readable_date="30 Sep 2017 15:05:48" contact_name="(Unknown)" />
<sms protocol="0" address="MPESA" date="1506855198658" type="1" subject="null" body="LJ14HATBG6 Confirmed. KshXXX sent to XXXX on 1/10/17 at 1:53 PM. New M-PESA balance is KshXXX. Transaction cost, KshXXX." toa="null" sc_toa="null" service_center="null" read="1" status="-1" locked="0" date_sent="1506855181000" sub_id="-1" readable_date="1 Oct 2017 13:53:18" contact_name="(Unknown)" />
</smses>
My initial implementation was filled with for-loops and was very slow, so I switched to using xml2. I am still cranky when using it, fumbling around I was able to hook up the function.
- Reading the xml using
read_xmlkinder obvious - Dropping down the nodes to the child nodes
xml_children, XML takes similar approach to html with a tree structure of sort. To save myself the trouble I usedxml_childrento read them all at once but if you know the name of the key you can usexml_child(doc, "keyname")to directly access a single key. - Pick the attributes from the child nodes
xml_attrs - Since picking attributes creates a list we convert it to a data frame
as.data.framethen transposet. - Notice I created an object
len_sizethis was to count the number of child attributes and picking the one with the highest count I pick that as the number of rows.
func_xml_work <- function(i){
xm_file <- xml2::read_xml(list_files[i])
xm_children <- xml_children(xm_file)
xm_list <- xml_attrs(xm_children)
len_size <- table(unlist(lapply(xm_list,length)))
dt <- as.data.frame(t(as.data.frame(xm_list[1:as.numeric(len_size[[1]])])), row.names = FALSE)
return(dt)
}Gymnastics we have a function that will read the XML file and convert it to a data frame. Now we need to see that it combines with the other XML files into one. That is where the party begins. You can opt either to:
- Read all files to R then merge them from R. The disadvantage it will not be prudent, memory optimization.
- Read the files and merge immediately, continuous merge as you load. This helps with memory optimization.
I opt for the second option, implementation is harder but reward is better memory optimization.
Second function func_merge_dt merging the xml files loaded to R on the go, simple procedure using bind_rows
dt_comb <- as.data.frame(NULL)
func_merge_dt <- function(len){
dt_temp <- func_xml_work(len)
dt_comb <- bind_rows(dt_temp)
#print(nrow(dt_temp))
return(dt_comb)
}
dt_comb <-map_dfr(1:length(list_files),func_merge_dt)Data munging
Finally we have the all the xmls loaded and saved as one data frame. Let the games begin.
Concentrate on the topic of the day, MPESA receipts. Good thing their is a variable address which makes this easier, filter data-set by MPESA.
I need to anonymise the receipts, leaving it with no personal identification information. Turn all names, amounts and phone numbers to XXX.
My preference is using stringr suite of functions because they are easy to manipulate strings. The name of the functions are even easier to remember. I tend to use a lot of regex for the data extraction.
dt_mpesa <- dt_comb %>%
filter(address == "MPESA")
dt_mpesa <- dt_mpesa %>%
distinct(body, .keep_all = TRUE)
##Anonymising the data ----
dt_mpesa$body <- dt_mpesa$body %>%
str_replace_all("\\+254","254")
str_replace("sent to ([:graph:]|[:space:]){0,} [:digit:]{0,} ", "sent to XXXX ") %>%
str_replace_all("Ksh([:digit:]|[:punctuation:]){0,}","KshXX.XX") %>%
str_replace("paid to ([:graph:]|[:space:]|[:digit:]){0,} on ", "paid to XXXX on ") %>%
str_replace_all("from\\s([:graph:]|[:space:]){0,}\\son", "from XXXX on") %>%
str_replace_all("from([:graph:]|[:space:]){0,}\\son", "from XXXX on") %>%
str_replace_all("kutoka\\s([:graph:]|[:space:]){0,}\\sMnamo ", "kutoka XXXX Mnamo ") %>%
str_replace_all("from\\s([:graph:]|[:space:]){0,}\\sNew\\sM", "from XXXX New M") %>%
str_replace("airtime for ([:digit:]){0,} on ", "airtime for XXXX on ") %>%
str_replace_all("cash\\sto\\s([:graph:]|[:space:]){0,}\\sNew\\sM", "cash to XXXX New M")Exploratory data analysis
First we load the anonymized data which I have made public. Then get our hands dirty with the grease.
Reduce the variables to just what we need
dt_mpesa <- read.xlsx("mpesa_trans.xlsx")
#dt_mpesa <- read.xlsx("../Rtest/Mpesa/mpesa_trans.xlsx")
#colnames(dt_mpesa)
dt_mpesa <- dt_mpesa %>%
select(c("address","date","body","readable_date"))
colnames(dt_mpesa)## [1] "address" "date" "body" "readable_date"Check randomly 5 cases/rows in the data-set. To have an idea of what we are working with. I will convert the data frame to a tibble, tibble have a nice format when shown in a markdown
dt_mpesa <- as_tibble(dt_mpesa)
sample_n(dt_mpesa, 5) %>%
knitr::kable("html")| address | date | body | readable_date |
|---|---|---|---|
| MPESA | 1425209771315 | GO30BZ885 Confirmed. KshXX.XX transferred to M-Shwari account on 1/3/15 at 2:18 PM. M-PESA balance is KshXX.XX new M-Shwari account balance is KshXX.XXFree airtime,dial 2346*2# | Mar 1, 2015 2:36:11 PM |
| MPESA | 1368860588036 | DM36RO627 confirmed. You bought KshXX.XX of airtime on 18/5/13 at 10:02 AM New M-PESA balance is KshXX.XXSafaricom only calls you from 0722000000 | May 18, 2013 10:03:08 AM |
| MPESA | 1379430767699 | DZ14QA577 Confirmed. KshXX.XX sent to XXXX on 17/9/13 at 6:12 PM New M-PESA balance is KshXX.XXPIN YAKO SIRI YAKO | Sep 17, 2013 6:12:47 PM |
| MPESA | 1556170855025 | NDP0GZZN5Q Confirmed.on 25/4/19 at 8:41 AMWithdraw KshXX.XX from 197951 - Olympic Conn Wa Mathew Cerials Shop Mwihoko New M-PESA balance is KshXX.XX Transaction cost, KshXX.XX | 25 Apr 2019 08:40:55 |
| MPESA | 1546431281548 | NA24WPVFVU Confirmed. KshXX.XX sent to XXXX on 2/1/19 at 3:14 PM. New M-PESA balance is KshXX.XX Transaction cost, KshXX.XX | 2 Jan 2019 15:14:41 |
We some data mining is needed to extract values from the string in body. Just have the right tool here for this and for me it is stringr.
What we are aiming for:
- Pick date
- Pick receipt number
stringr function str_extract will be our favorite out of the box tool. For extracting the values. After which we shall filter down the data to only actual receipt numbers.
dt_mpesa["receipt_no"] <- dt_mpesa$body %>% str_extract("\\w+")
dt_mpesa["receipt_dig2"] <- dt_mpesa$receipt_no %>% str_extract("[A-Z]{0,2}")
dt_mpesa["act_date"] <- dt_mpesa$body %>% str_extract("[0-9]{1,2}\\/[0-9]{1,2}\\/[0-9]{1,2}")
dt_mpesa["year"] <- dt_mpesa$readable_date %>% str_extract("[0-9][0-9][0-9][0-9]")
dt_mpesa$act_date <- dt_mpesa$act_date %>% dmy()
dt_mpesa <- dt_mpesa %>%
filter(!(receipt_no %in% c("Failed","Transaction","You","Your","To","BRIAN","An")))
dt_mpesa <- dt_mpesa %>%
filter(!is.na(month(dt_mpesa$act_date)))
dt_mpesa <- dt_mpesa[nchar(dt_mpesa$receipt_dig2) == 2,]
dt_mpesa["receipt_dig1"] <- substr(dt_mpesa$receipt_dig2,1,1)
sample_n(dt_mpesa, 5) %>%
knitr::kable("html")| address | date | body | readable_date | receipt_no | receipt_dig2 | act_date | year | receipt_dig1 |
|---|---|---|---|---|---|---|---|---|
| MPESA | 1522742122510 | MD35M5NA55 Confirmed. KshXX.XX sent to XXXX on 3/4/18 at 10:55 AM New M-PESA balance is KshXX.XX Transaction cost, KshXX.XX | 3 Apr 2018 10:55:22 | MD35M5NA55 | MD | 2018-04-03 | 2018 | M |
| MPESA | 1546079689978 | MLT1TUFIHH Confirmed.You have received KshXX.XX from XXXX on 29/12/18 at 1:34 PM New M-PESA balance is KshXX.XX Pay bills via M-PESA. | 29 Dec 2018 13:34:49 | MLT1TUFIHH | ML | 2018-12-29 | 2018 | M |
| MPESA | 1391712130888 | EP36EZ708 Confirmed. KshXX.XX transferred to M-Shwari account on 6/2/14 at 6:47 PM. M-PESA balance is KshXX.XX new M-Shwari account balance is KshXX.XX | Feb 6, 2014 9:42:10 PM | EP36EZ708 | EP | 2014-02-06 | 2014 | E |
| MPESA | 1509188451694 | LJS4WBC3W4 Confirmed. KshXX.XX sent to XXXX on 28/10/17 at 2:00 PM. New M-PESA balance is KshXX.XX Transaction cost, KshXX.XX | 28 Oct 2017 14:00:51 | LJS4WBC3W4 | LJ | 2017-10-28 | 2017 | L |
| MPESA | 1526921897093 | MEL0J5WTRI Confirmed. KshXX.XX sent to XXXX on 21/5/18 at 7:58 PM New M-PESA balance is KshXX.XX Transaction cost, KshXX.XX | 21 May 2018 19:58:17 | MEL0J5WTRI | ME | 2018-05-21 | 2018 | M |
Now we have our data arranged in formats we would like. Let us see what we can deduce from the data
count(dt_mpesa, year) %>%
knitr::kable("markdown")| year | n |
|---|---|
| 2012 | 59 |
| 2013 | 371 |
| 2014 | 559 |
| 2015 | 193 |
| 2017 | 128 |
| 2018 | 340 |
| 2019 | 409 |
| 2020 | 7 |
ggplot(dt_mpesa, aes(x = year)) +
geom_bar(colour = "green") +
geom_text(aes(label = ..count..), stat = "count",
vjust = 1.5, colour = "white") +
ylab("Number of transactions") +
ggtitle("Frequency of Transactions", "Oct 2012 - Jan 2020")## Warning: The dot-dot notation (`..count..`) was deprecated in ggplot2 3.4.0.
## ℹ Please use `after_stat(count)` instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.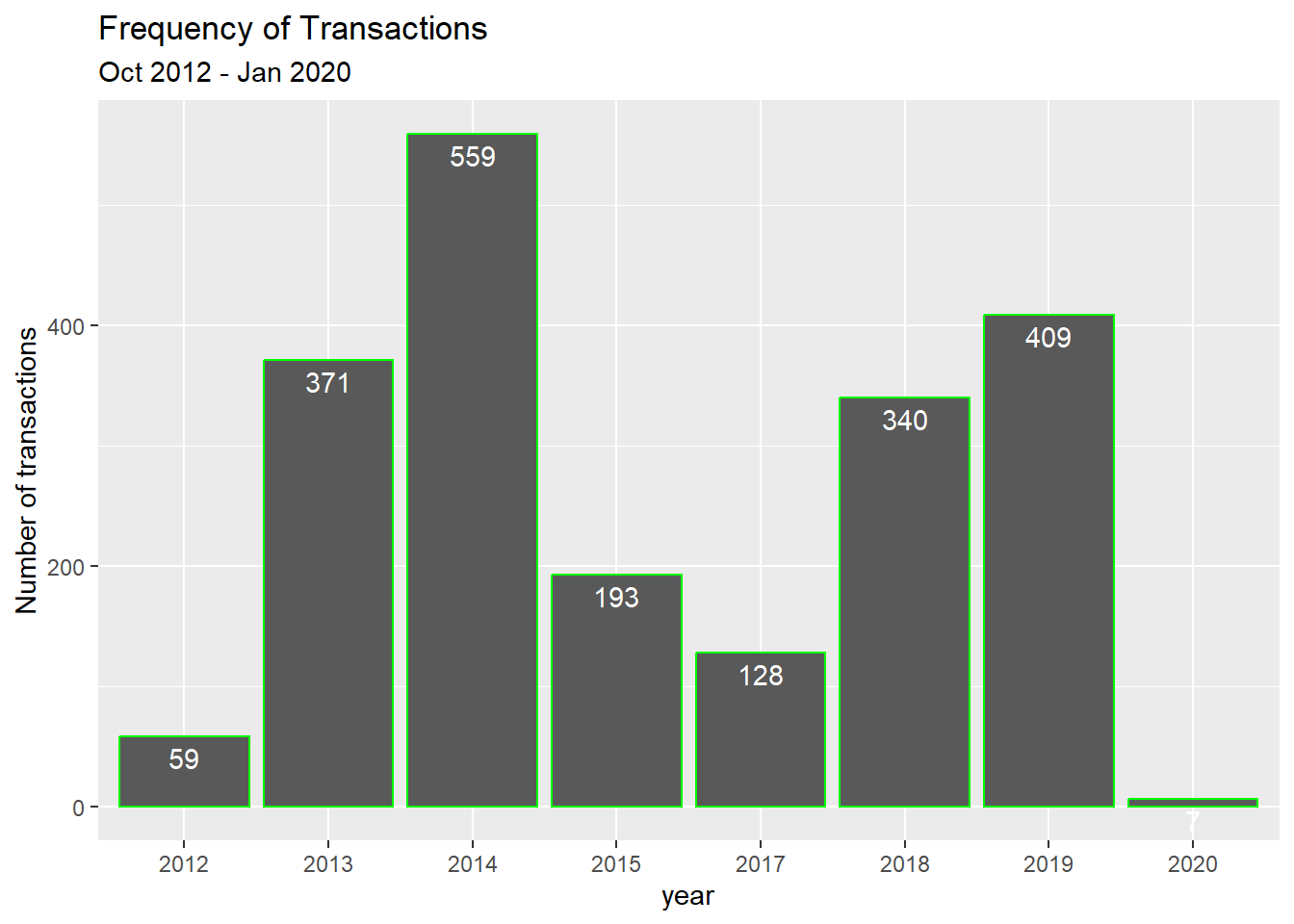
The first letter is the year. Let us test that.
dt_mpesa %>%
group_by(year) %>%
count(first_letter = receipt_dig1) %>%
knitr::kable("markdown")| year | first_letter | n |
|---|---|---|
| 2012 | C | 59 |
| 2013 | C | 4 |
| 2013 | D | 234 |
| 2013 | E | 133 |
| 2014 | E | 118 |
| 2014 | F | 372 |
| 2014 | G | 69 |
| 2015 | G | 154 |
| 2015 | J | 39 |
| 2017 | L | 128 |
| 2018 | M | 340 |
| 2019 | N | 409 |
| 2020 | O | 7 |
dt_mpesa <- dt_mpesa %>% ungroup()
ggplot(dt_mpesa, aes(x = year, y = receipt_dig1)) +
geom_segment(aes(yend = receipt_dig1), xend = 0, colour = "grey50") +
geom_point(colour = "green", size = 5) +
theme_bw() +
theme(
panel.grid.major.y = element_blank()
) +
ylab("First Letter in Receipt Number") +
ggtitle("Year vs First Letter","Which first letters are in every year")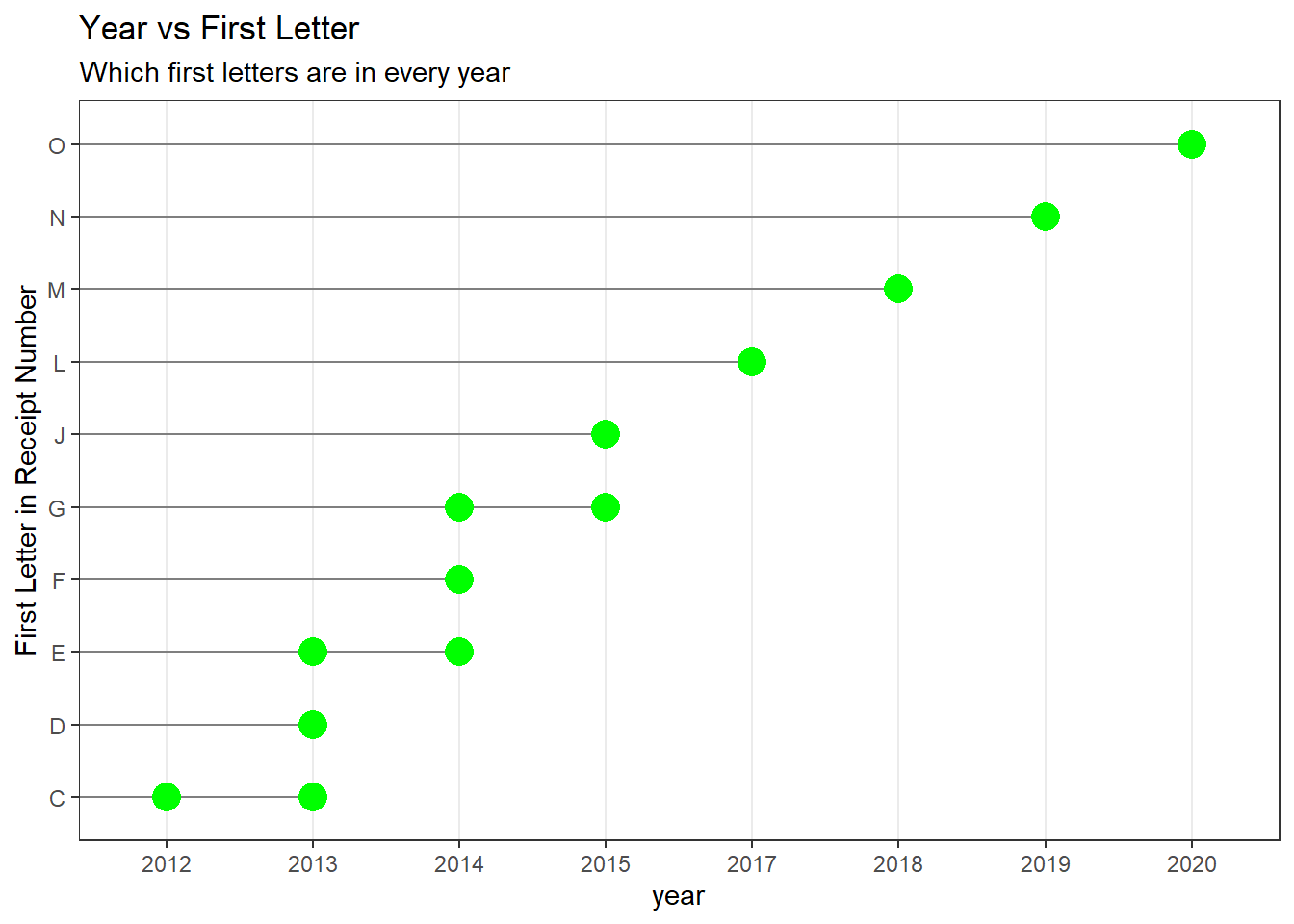
The second letter stands for the month. Is that the case let us see.
dt_mpesa %>%
group_by(year,month = month(act_date)) %>%
count(two_digit = receipt_dig2) %>%
as_tibble() %>%
sample_n(5) %>%
knitr::kable("markdown")| year | month | two_digit | n |
|---|---|---|---|
| 2014 | 1 | EO | 2 |
| 2013 | 12 | EH | 8 |
| 2013 | 10 | EA | 6 |
| 2014 | 11 | GA | 17 |
| 2013 | 7 | DQ | 5 |
dt_mpesa <- dt_mpesa %>% ungroup()